分析侧重于模型推理,而不是训练,因此只是整个机器学习过程的一小部分。我们的工作侧重于模型部署,因此模型的权重已经过预训练,我们使用推理过程来生成输出。
试图将nano-gpt抽象为通用矩阵乘法(GEMM),稀疏矩阵-矩阵乘法(SpMM),通用矩阵-向量乘法(GEMV),稀疏矩阵-向量乘法(SpMV) ,采样-密集-密集矩阵乘法(SDDMM)(SDDMM用于处理稀疏矩阵与密集矩阵之间的乘积,但在NanoGPT中可能由于轻量级设计的原因,可能不会使用这种高级的矩阵运算。)
Embedding过程
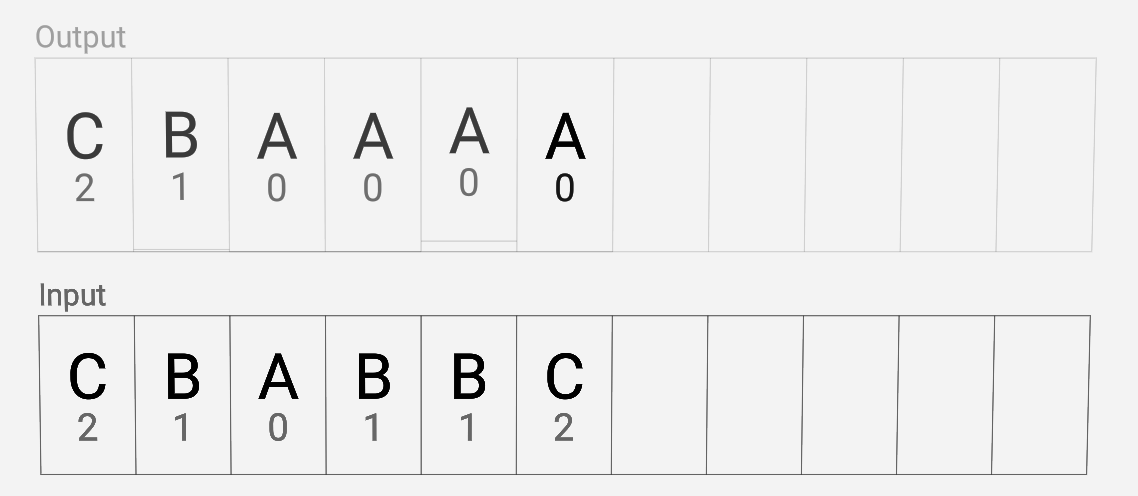
通过将输入CBABBC以字母表顺序排序为例。
输入串:1 * T
Token Embedding matrix:C * n_vocab (C为超参数也被称为“特征”或“尺寸”或“嵌入大小”,由设计者选择,以在模型大小和性能之间进行权衡。n_vocab为词汇表大小)
Position Embedding matrix:C * T
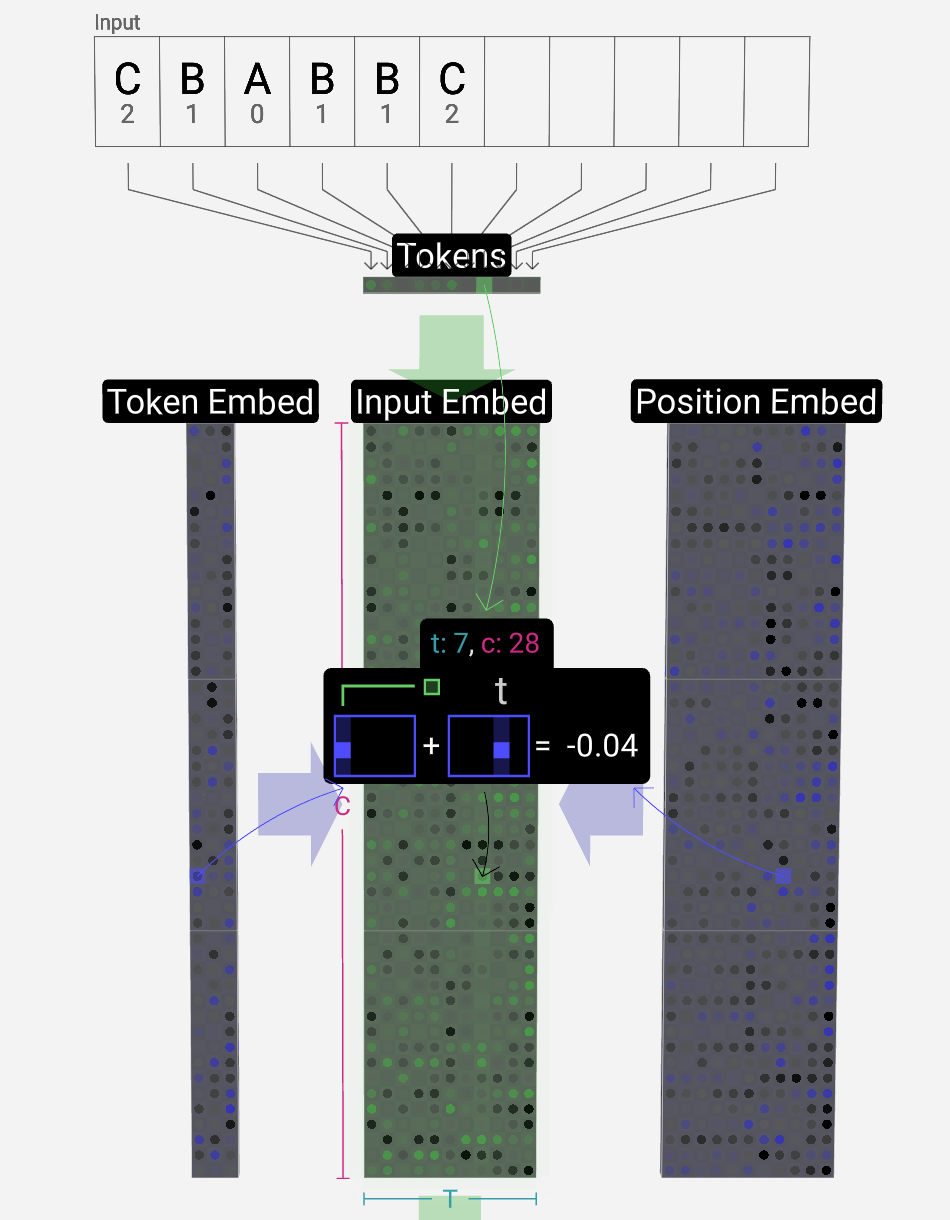
矩阵-矩阵列相加运算(vec + vec):T次
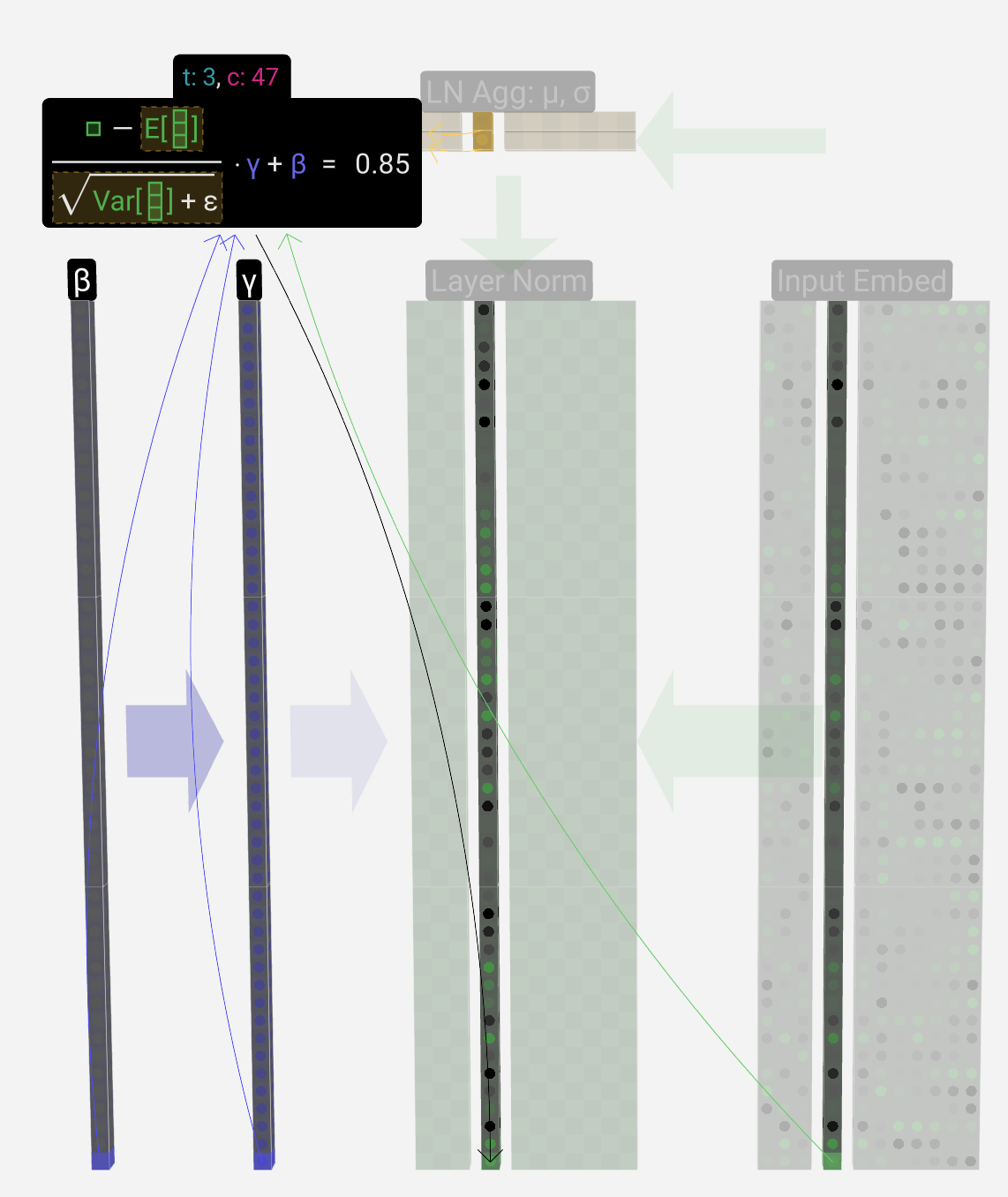
Layer-Norm
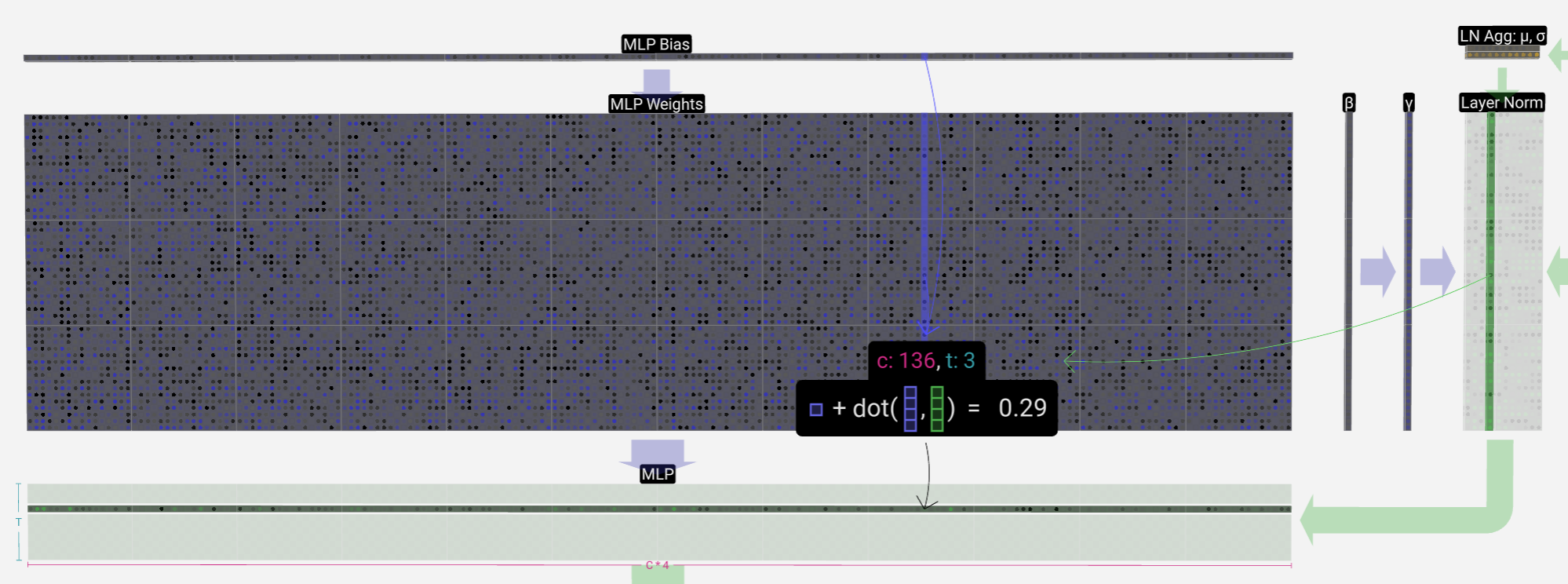
Transformer块中的第一步是矩阵应用Layer-Norm,这是一个分别规范化矩阵每列中的值的操作。
以第三列为例(0为首序号)
目标是使列中的平均值等于0,标准偏差等于1。为此,我们找到该列的这两个量(平均值(μ)和标准差(σ)),然后减去平均值并除以标准偏差
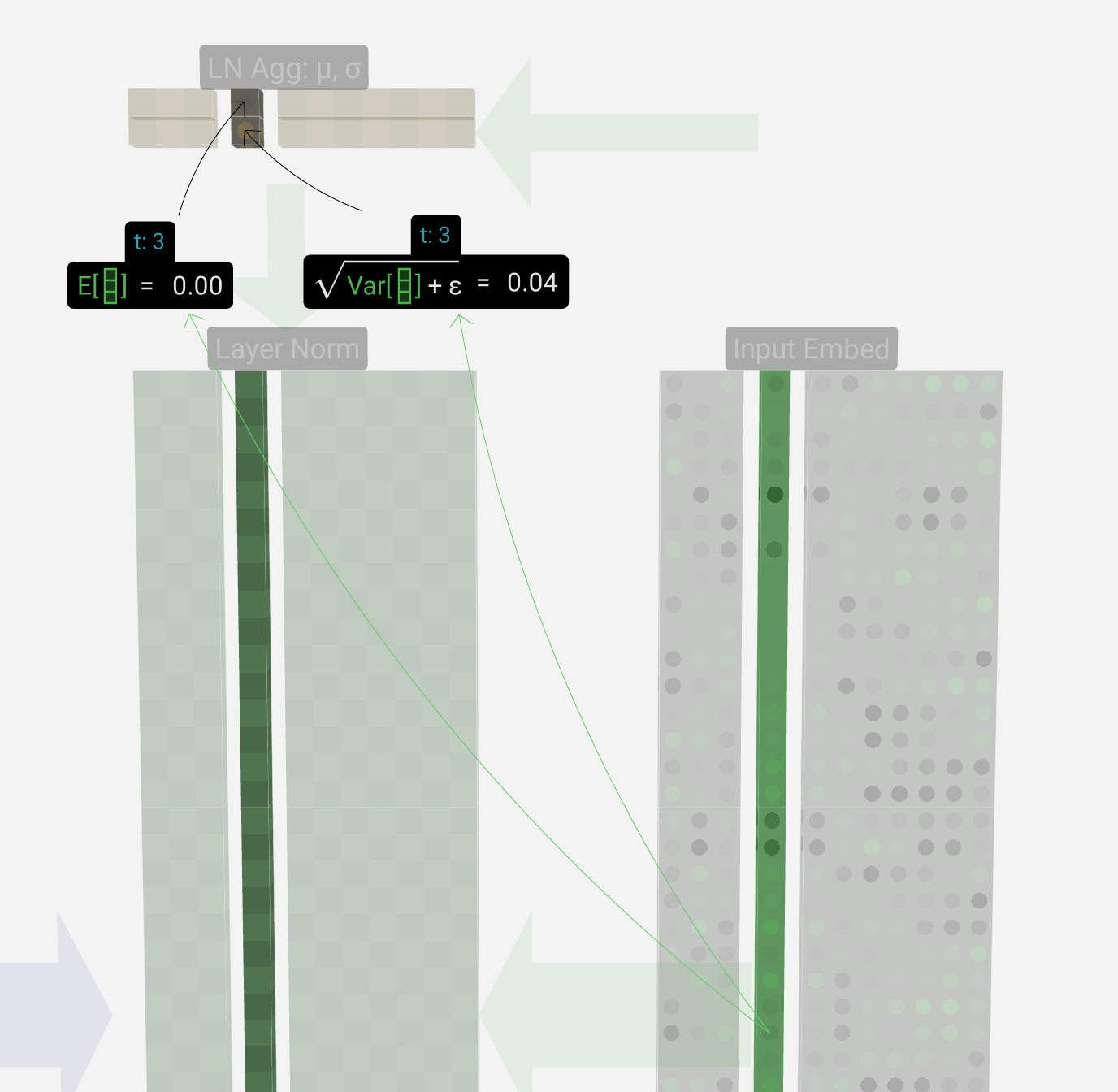
计算均值和标准差非矩阵运算过程
E[x]表示平均值,Var[x]用于方差(长度为C的列)ε项(ε=1×10-5)用于防止被零除。 我们计算这些值并将其存储在LN Agg中 有了归一化值,我们将列中的每个元素乘以训练过程中学习到的权重(γ),然后加上偏差(β)值,得到我们的归一化值。
vec + vec : C * T * transformer_nums * 2次
self- attention层
在自注意力(self-attention)机制中,头数(number of heads)是一个超参数,指定了每个注意力层中多头自注意力的数量。在Transformer模型中,每个注意力层会分为多个头(通常是8个或者16个头),每个头会学习到不同的注意力权重,然后这些头的输出会被拼接或者叠加起来,形成最终的注意力表示。
头数的选择是一个重要的超参数,它决定了模型在抽取不同关注点方面的能力。通常情况下,更多的头数可以增加模型的表达能力,提高对不同位置、不同特征的关注能力,但也会增加计算量和模型参数的数量。在实践中,头数的选择会根据具体的任务和资源情况进行调节。
自注意力层由几个头部组成,我们现在关注其中一个。
获得Q、K、V vectors过程
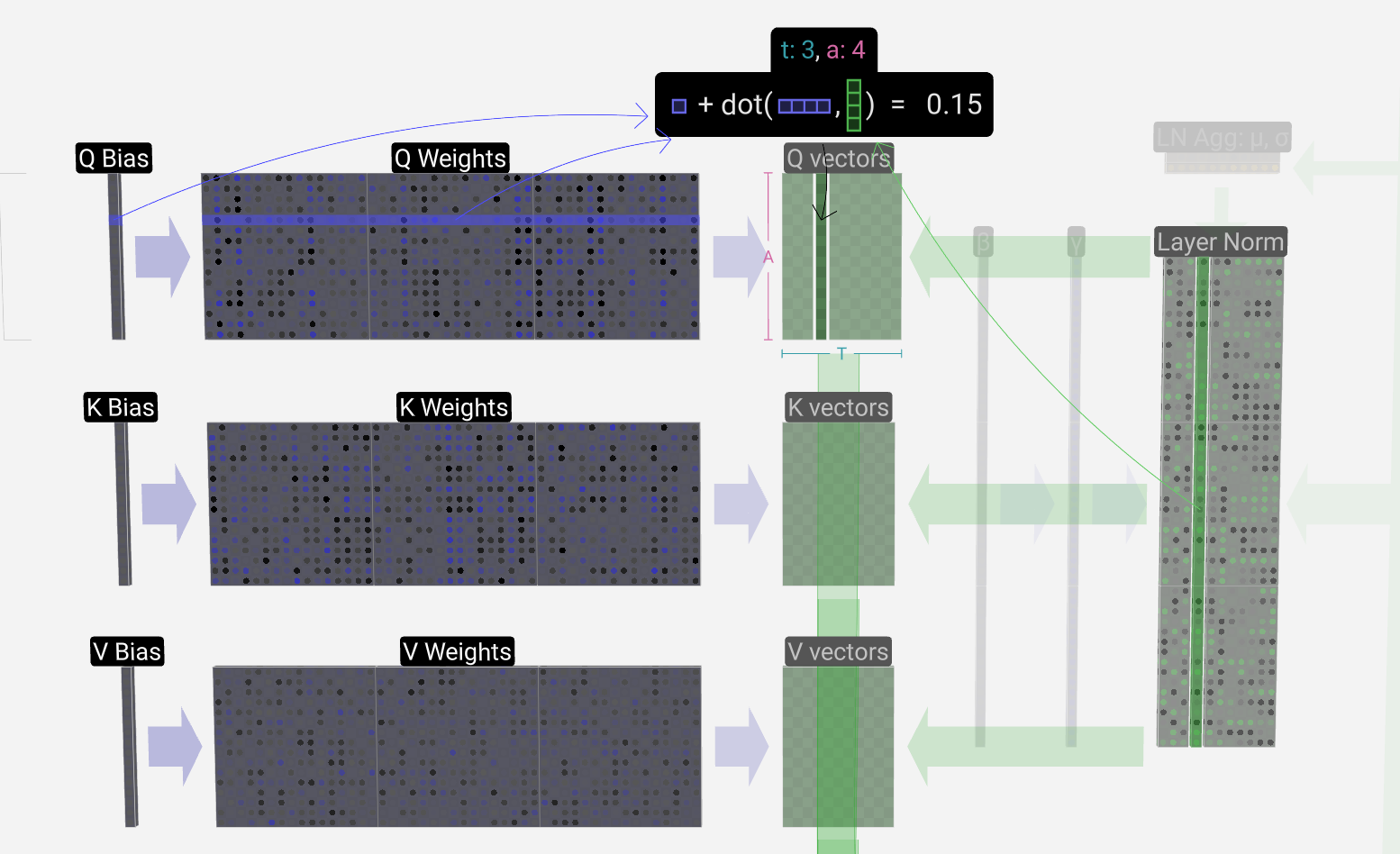
带偏置的矩阵矩阵乘法(GEMM、vec + vec): 3 * heads_num * transformer_num次、3T * heads_num * transformer_num次
获得Attention Matirx
计算当前列(t=5)的Q矢量和这些先前列中的每一列的K矢量之间的点积。然后将这些存储在注意力矩阵的相应行(t=5)中。
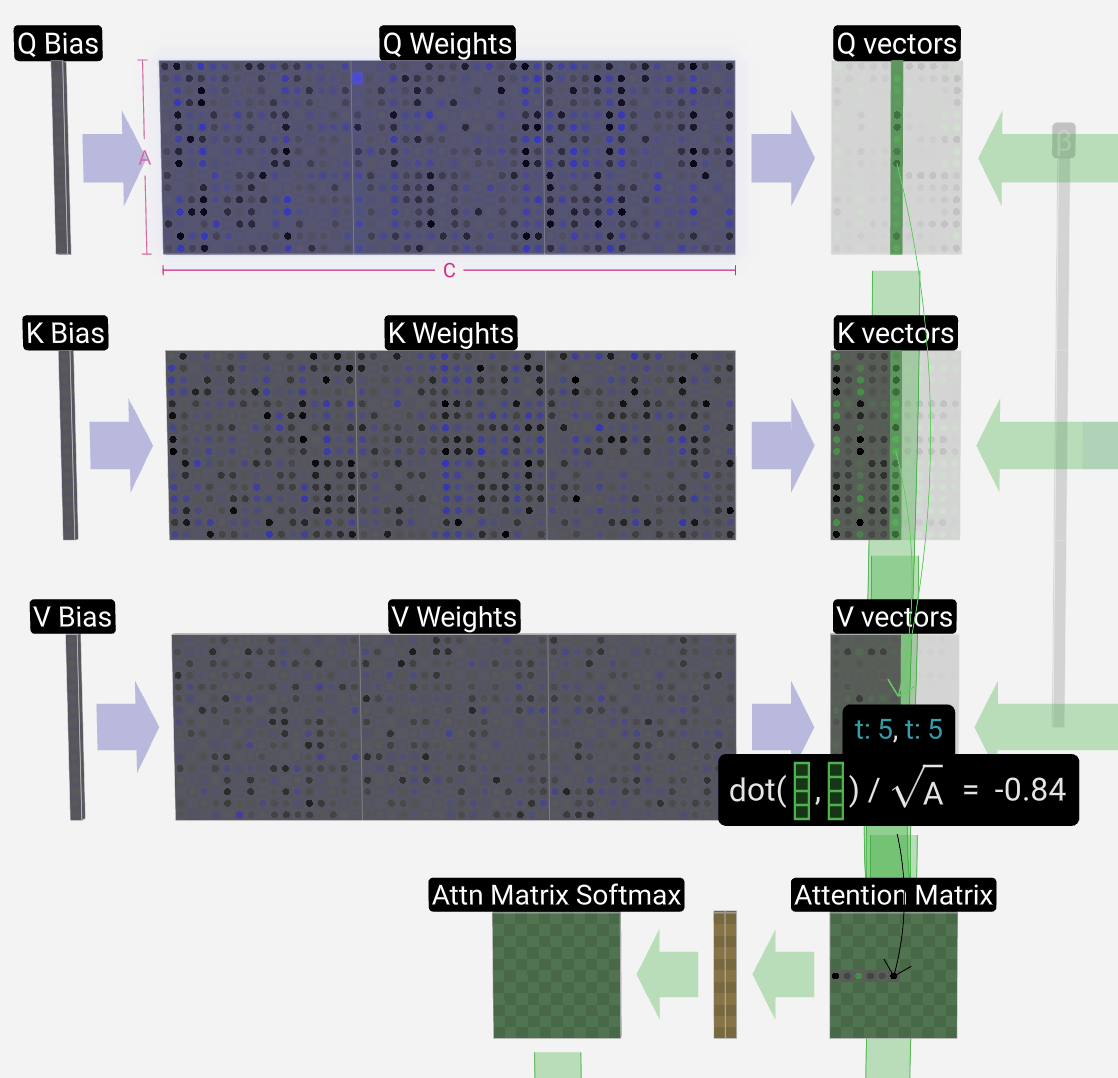
Q vectors的转置矩阵和K vectors矩阵的乘法,然后将结果矩阵的右上角清零(GEMM):heads_num * transformer_num次
获得Attn Matrix softmax
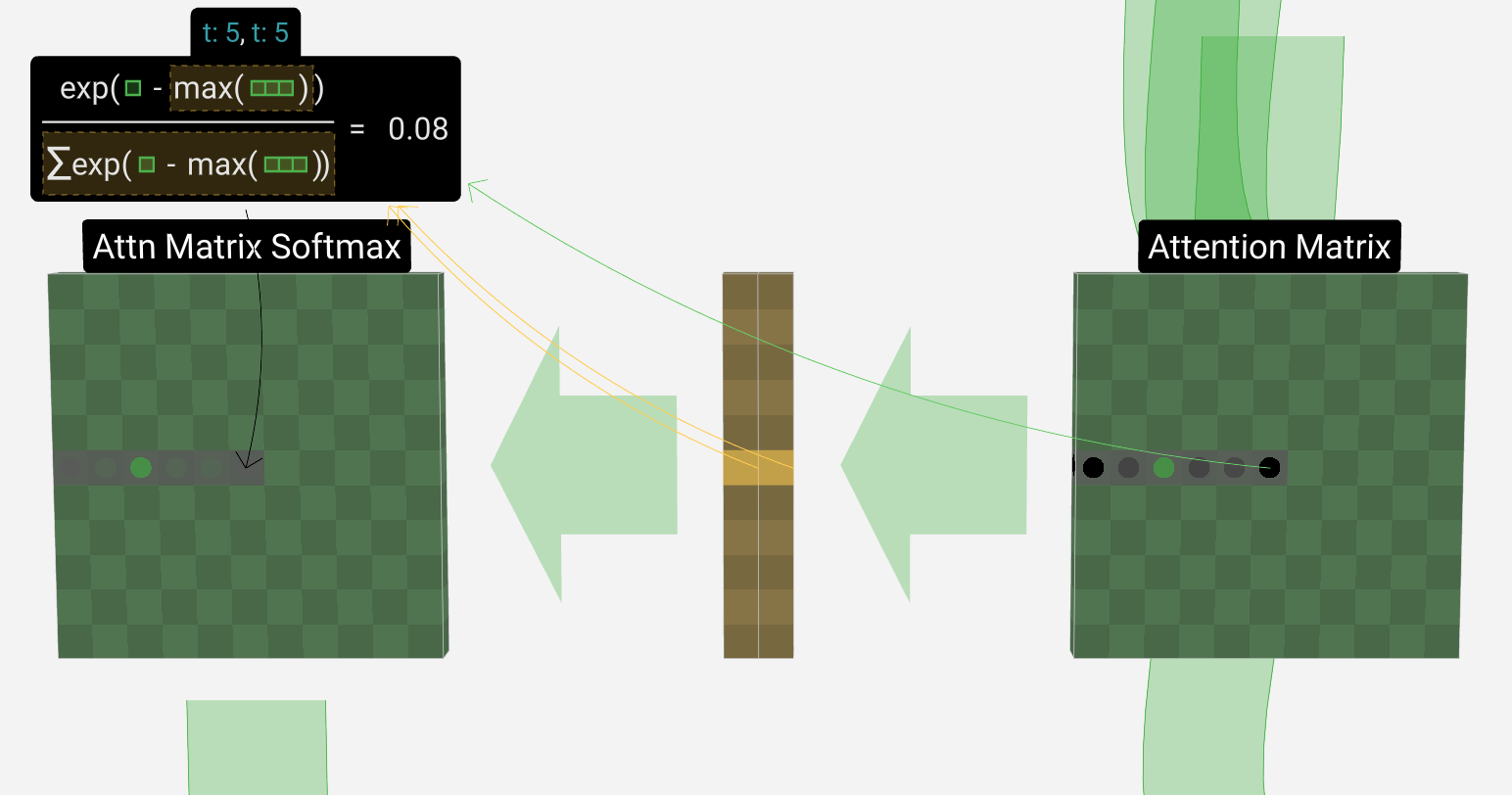
无矩阵运算
获得V Output
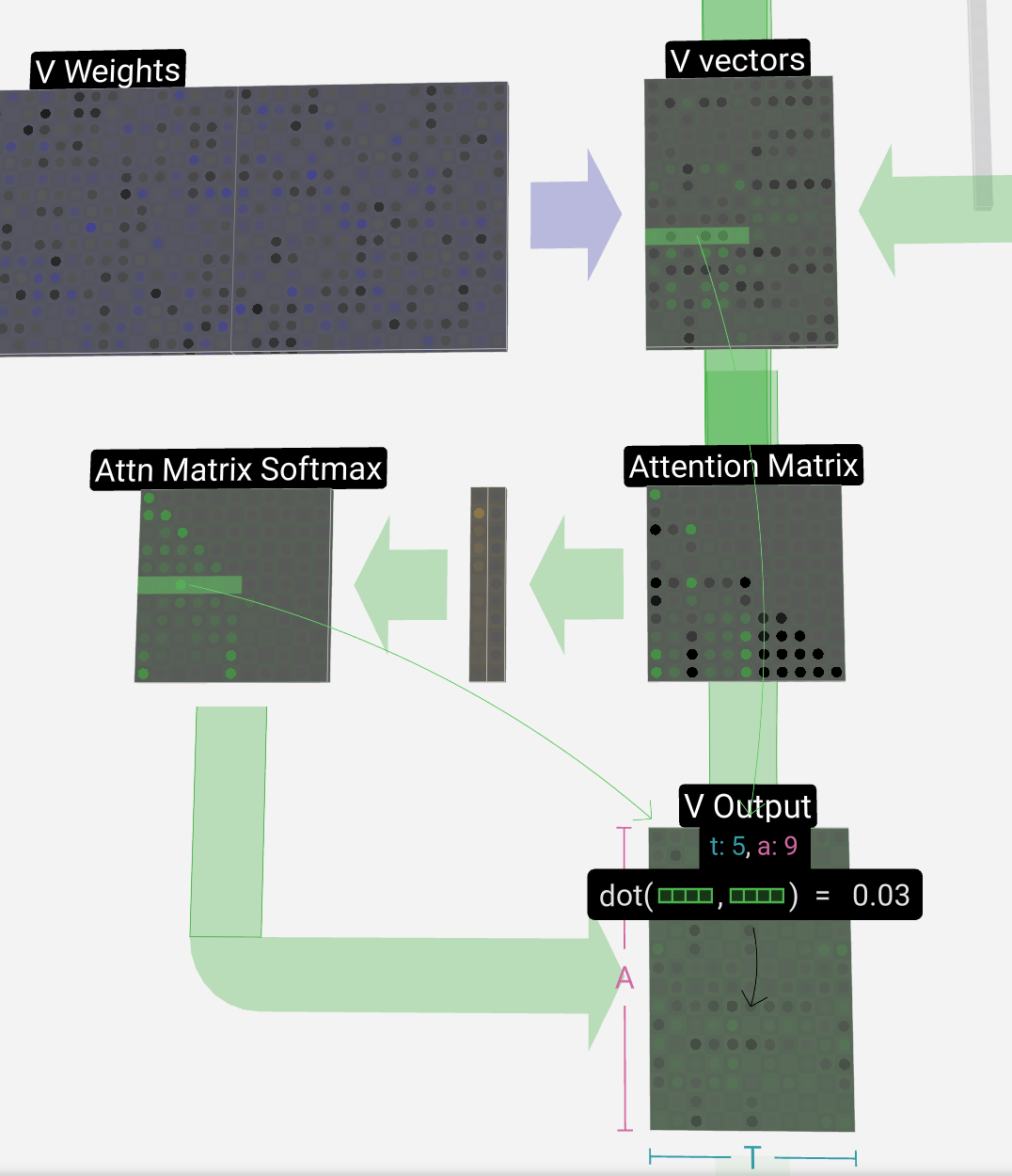
V vectors与Attn Matrix softmax的转置的乘法(SpMM):head_nums * transformer_nums次
Projection层
在自注意过程之后,我们得到了每个head的输出。这些输出是受Q和K影响的适当混合V的vectors。 为了组合每个head的输出vectors,我们只需将它们堆叠在一起。值得注意的是,在GPT中,head内向量的长度(a=16)等于C / num_heads。这确保了当重新堆叠在一起时得到原始长度C。
获得attention output
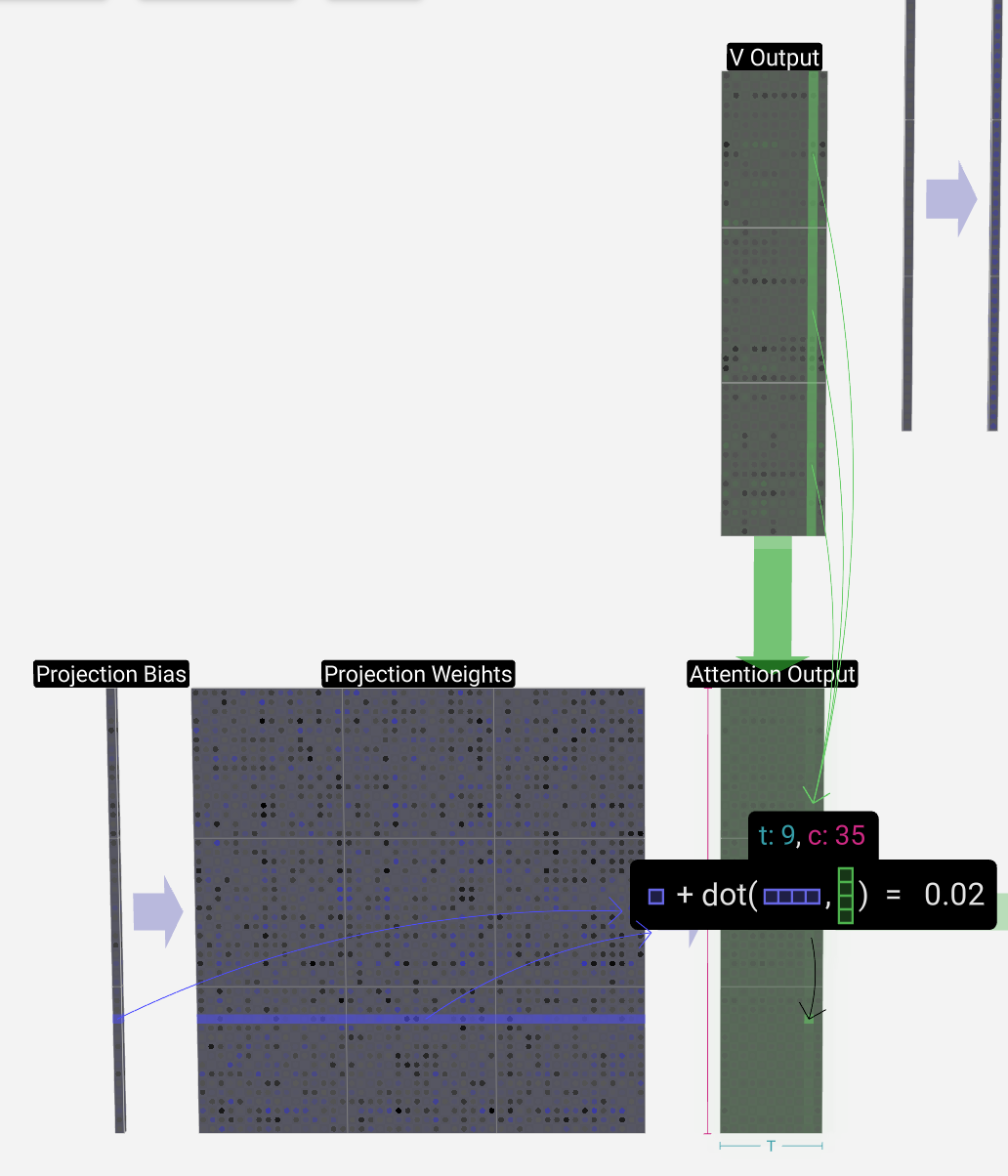
有偏置量的矩阵矩阵乘法(GEMM、vec + vec):transformer_nums次、T * transformer_nums次
获得attention residual
有了自注意层的输出。我们不将此输出直接传递到下一阶段,而是将其逐元素添加到input embed中,运算为矩阵加法
MLP层(多层感知机)
首先将Attention residual转变为Layer Norm
-
A linear transformation with a bias added, to a vector of length 4 * C.
有偏置的矩阵乘法(GEMM、vec + vec):transformer_nums次、T * transformer_nums次
-
A GELU activation function (element-wise)
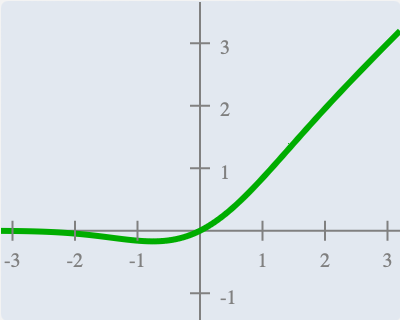
对MLP矩阵使用,对每个元素使用GELU函数,引入非线性
-
A linear transformation with a bias added, back to a vector of length C

有偏置的矩阵乘法(GEMM、vec + vec):transformer_nums次、T * transformer_nums次
获得MLP residual
与获得Attention residual一样,进行element- wise的加法
多个完整的transformer(layer norm —>多头随机自注意力机制 multi-head,causal self-attention —>layer norm —> 前馈网络 feed forward)形成了任何GPT模型的主体,并重复多次,一个块的输出进入下一个块,继续剩余的路径。 正如深度学习中常见的那样,很难说这些层中的每一层到底在做什么,但有一些总体想法:早期的层往往专注于学习较低级别的特征和模式,而后期的层则学习识别和理解更高级别的抽象和关系。在自然语言处理的背景下,较低层可能学习语法、句法和简单的单词联想,而较高层可能捕捉更复杂的语义关系、话语结构和上下文相关的含义。
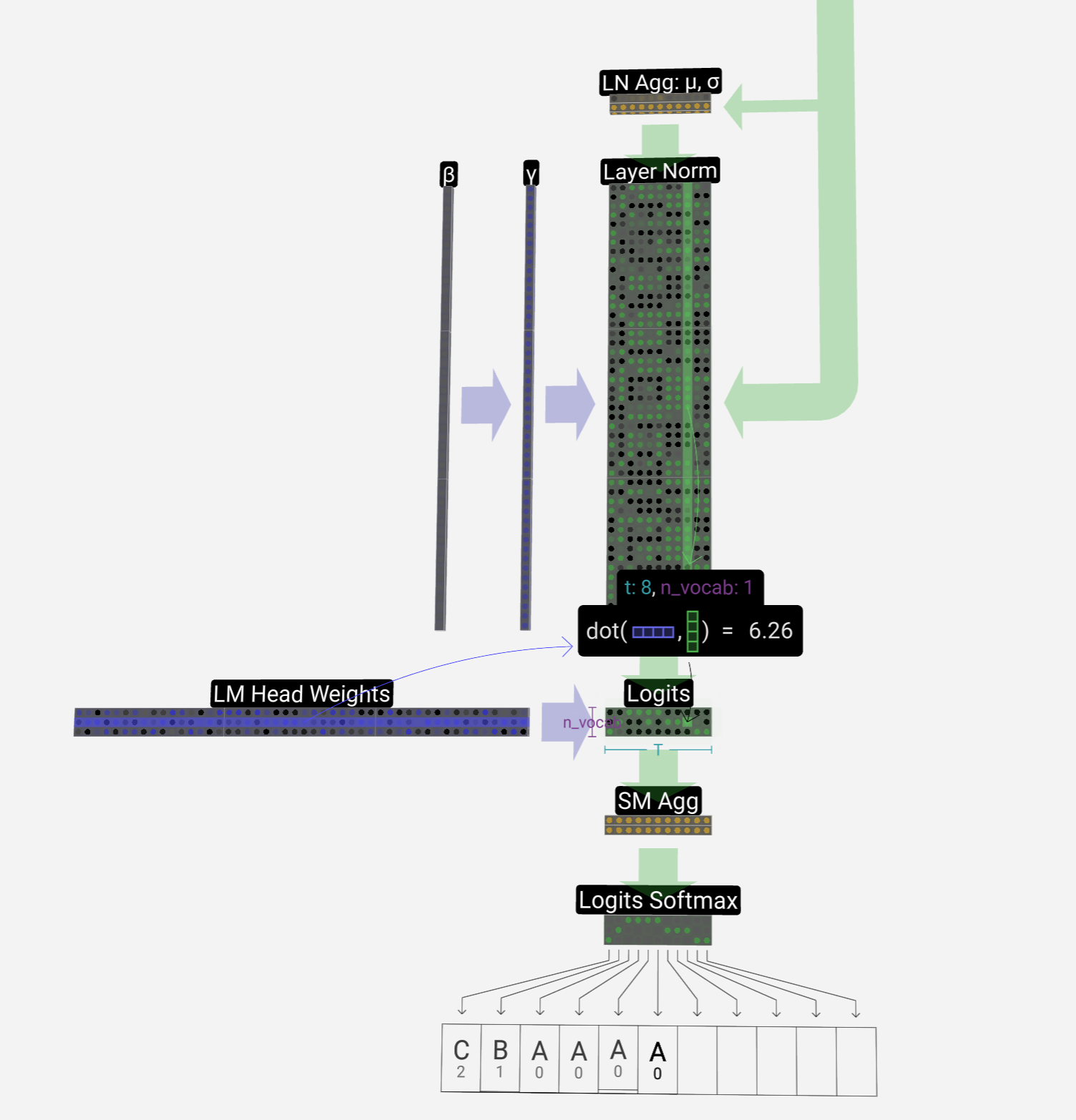
Softmax & Output
后面将结果进入layer-norm后,进入linear和softmax、最终得到结果