
学习whu DB课程的笔记
详细的例子比起定义更好理解
看廖雪峰Sql博客的一点记录
主键
主键是关系表中记录的唯一标识。主键的选取非常重要:主键不要带有业务含义,而应该使用BIGINT自增或者GUID类型。主键也不应该允许NULL。
可以使用多个列作为联合主键,但联合主键并不常用。
没有必要的情况下,我们尽量不使用联合主键,因为它给关系表带来了复杂度的上升。
外键
在students表中,通过class_id的字段,可以把数据与另一张表关联起来,这种列称为外键。
外键并不是通过列名实现的,而是通过定义外键约束实现的:
ALTER TABLE students
ADD CONSTRAINT fk_class_id
FOREIGN KEY (class_id)
REFERENCES classes (id);
其中,外键约束的名称fk_class_id可以任意,FOREIGN KEY (class_id)指定了class_id作为外键,REFERENCES classes (id)指定了这个外键将关联到classes表的id列(即classes表的主键)。
通过定义外键约束,关系数据库可以保证无法插入无效的数据。即如果classes表不存在id=99的记录,students表就无法插入class_id=99的记录。
由于外键约束会降低数据库的性能,大部分互联网应用程序为了追求速度,并不设置外键约束,而是仅靠应用程序自身来保证逻辑的正确性。这种情况下,class_id仅仅是一个普通的列,只是它起到了外键的作用而已。
要删除一个外键约束,也是通过ALTER TABLE实现的:
ALTER TABLE students
DROP FOREIGN KEY fk_class_id;
注意:删除外键约束并没有删除外键这一列。删除列是通过DROP COLUMN ...实现的。
条件查询
条件查询的语法就是:
SELECT * FROM <表名> WHERE <条件表达式>
投影查询
使用SELECT *表示查询表的所有列,使用SELECT 列1, 列2, 列3则可以仅返回指定列,这种操作称为投影。
SELECT语句可以对结果集的列进行重命名。
排序
查询结果集通常是按照id排序的,也就是根据主键排序。这也是大部分数据库的做法。
如果我们要根据其他条件排序怎么办?可以加上ORDER BY子句。例如按照成绩从低到高进行排序:
SELECT id, name, gender, score
FROM students
ORDER BY score;
按照成绩从高到底排序,我们可以加上DESC表示“倒序”:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC;
如果score列有相同的数据,要进一步排序,可以继续添加列名。例如,使用ORDER BY score DESC, gender表示先按score列倒序,如果有相同分数的,再按gender列排序:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC, gender;
如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面。
分页查询
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 0;
上述查询LIMIT 3 OFFSET 0表示,对结果集从0号记录开始,最多取3条。注意SQL记录集的索引从0开始。
如果要查询第2页,那么我们只需要“跳过”头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 3;
-
OFFSET计算公式为pageSize * (pageIndex - 1)。 -
LIMIT总是设定为pageSize。
使用LIMIT <M> OFFSET <N>可以对结果集进行分页,每次查询返回结果集的一部分;
分页查询需要先确定每页的数量和当前页数,然后确定LIMIT和OFFSET的值。
聚合查询
| 函数 | 说明 |
|---|---|
| SUM | 计算某一列的合计值,该列必须为数值类型 |
| AVG | 计算某一列的平均值,该列必须为数值类型 |
| MAX | 计算某一列的最大值 |
| MIN | 计算某一列的最小值 |
| COUNT | 计算元组个数 |
注意:MAX()和MIN()函数并不限于数值类型。如果是字符类型,MAX()和MIN()会返回排序最后和排序最前的字符。
要特别注意:如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL:
eg:
SELECT AVG(score) average
FROM students
WHERE gender = 'M'
//分组查询例子
SELECT class_id, gender,AVG(score) AverageScore
From students
Group by class_id,gender;
//结果如下
| class_id | gender | AverageScore |
|---|---|---|
| 1 | M | 89 |
| 1 | F | 84 |
| 2 | F | 81 |
| 2 | M | 70 |
| 3 | F | 89.5 |
| 3 | M | 89 |
多表查询
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
假设查询语句是:
SELECT ...
FROM tableA
??? JOIN tableB
ON tableA.column1 = tableB.column2;
我们把tableA看作左表,把tableB看成右表,那么INNER JOIN是选出两张表都存在的记录:
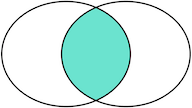
LEFT OUTER JOIN是选出左表存在的记录:
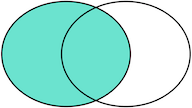
RIGHT OUTER JOIN是选出右表存在的记录:
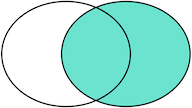
FULL OUTER JOIN则是选出左右表都存在的记录:
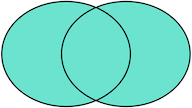
INSERT
INSERT INTO students (class_id, name, gender, score)
VALUES
(1, '大宝', 'M', 87),
(2, '二宝', 'M', 81);
注意到我们并没有列出id字段,也没有列出id字段对应的值,这是因为id字段是一个自增主键,它的值可以由数据库自己推算出来。此外,如果一个字段有默认值,那么在INSERT语句中也可以不出现。
UPDATE
UPDATE students
SET name='大牛', score=66
WHERE id=1;
UPDATE students
SET name='小牛', score=77
WHERE id>=5 AND id<=7;
UPDATE students
SET score=score+10
WHERE score<80;
如果WHERE条件没有匹配到任何记录,UPDATE语句不会报错,也不会有任何记录被更新
delete
DELETE
FROM students
WHERE id>=5 AND id<=7;
不带WHERE条件的DELETE语句会删除整个表的数据:
DELETE FROM students;
Mysql 终端管理
mysql -u root -p //连接本地数据库(已经将mysql添加到环境变量)
mysql>SHOW DATABASES;//大小都行
mysql>CREATE DATABASE test;//创建数据库
mysql>DROP DATABASE test;// 删除数据库
mysql>USE test; // Database changed
mysql>SHOW TABLES;
mysql>DESC students; // 查看表结构
mysql>SHOW CREATE TABLE students; // 查看创建表的sql语句
mysql>DROP TABLE students; // 删除表
mysql>ALTER TABLE students ADD COLUMN birth varchar(10) not null;
//给students表新增一列birth
mysql>ALTER TABLE students CHANGE COLUMN birth birthday varchar(20) not null; //要修改birth列,例如把列名改为birthday,类型改为VARCHAR(20)
mysql>ALTER TABLE students DROP COLUMN birthday; //删除列
mysql> exit; //注意EXIT仅仅断开了客户端和服务器的连接,MySQL服务器仍然继续运行
information_schema、mysql、performance_schema和sys是系统库,不要去改动
WHU SQL
sql数据定义
表的建立和删除
1. 表的建立
CREATE TABLE Student
( son CHAR(5) NOT NULL,
sname CHAR(8) NOT NULL,
sex CHAR(2),
age SMALLINT,
dept CHAR(20)
PRIMARY KEY(sno),
CHECK sex IN('男','女')
);
CREATE TABLE Course
( cno CHAR(4),
cname CHAR(4) NOT NULL,
pcno CHAR(4),
credit SMALLINT,
PRIMARY KEY(cno),
FOREIGN KEY(pcno) REFERENCES Course(cno)
);
CREATE TABLE SC
( sno CHAR (5),
cno CHAR (4) ,
grade SMALLINT,
PRIMARY KEY (sno,cno),
FOREIGN KEY (sno)REFERENCES Student(sno),
FOREIGN KEY (cno)REFERENCES Course(cno),
CHECK ((grade IS NULL) OR (grade BETWEEN 0 AND 100))
);
2. 表的删除
DROP TABLE <表名> [CASCADE | RESTRICT]
RESTRICT确保只有不具有相关对象的表才能被撤销
eg:
DROP TABLE St-quit CASCADE;
表的扩充和修改
ALTER TABLE <表名>
[ADD <新列名><数据类型>[完整性约束]]
[DROP<列名>[<完整性约束名>]]
[MODIFY<列名> <数据类型><数据类型>];
<表名>指定需要修改的基本表
ADD子句用于增加新列和新的完整性约束条件
DROP子句用于删除指定的列和完整性约束条件
MODIFY子句用于修改原有的列定义。
1. 在表中增加新列
ALTER TABLE Student
ADD(place CHAR(20), addr CHAR(20));
2. 删除列
ALTER TABLE Student
DROP addr;
3. 修改原有列的类型
ALTER TABLE Student
MODIFY place CHAR(8);
4. 补充定义主键
ALTER TABLE <table name>
ADD PRIMARY KEY(<col name>);
5. 删除主键
ALTER TABLE <table name>
DROP PRIMARY KEY;
域定义
用于建立用户自定义的数据类型
CREATE DOMAIN <域名> [AS] <数据类型>
[DEFAULT <缺省值>]
[<域约束>]
CREATE DOMAIN item_id NUMBERIC(4) DEFAULT 0
CHECK (VALUE IS NOT NULL)
索引建立与删除
基本表上建立一个或多个索引,以提供多种存取路径,加快查找速度
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名><次序>[[,<列名><次序>]]...);
次序: 升序(ASC,缺省) 降序(DESC)
UNIQUE: 每一个索引值只对应惟一的数据记录。
CLUSTER: 建立聚簇索引,即索引项的顺序与表中记录的物理顺序一致。
DROP INDEX<索引名>
在一个基本表上最多只能建立一个聚簇索引
经常更新的列不宜建立聚簇索引
eg:
① 为Student表按学号升序建惟一聚簇索引。
② 为SC表按学号升序和课程号降序建惟一索引。
CREATE UNIQUE CLUSTER INDEX Stno ON Student(Sno);
CREATE UNIQUE INDEX Scno ON SC(Sno ,Cno DESC);