
之前,我们研究了内核如何管理用户进程的虚拟内存,但文件和I/O被遗漏了。这篇文章涵盖了文件和内存之间重要且经常被误解的关系及其对性能的影响。
当涉及到文件时,操作系统必须解决两个严重的问题。第一个是硬盘驱动器令人震惊的缓慢,特别是相对于内存的磁盘寻求。第二是需要在物理内存中加载一次文件内容,并在程序之间共享内容。如果您使用进程资源管理器查看Windows进程,您将看到每个进程中都加载了约15MB的常见DLL。我的Windows box现在运行100个进程,所以如果不共享,我将仅为常见的DLL使用高达 1.5 GB的物理RAM。不好。同样,几乎所有的Linux程序都需要ld.so和libc,以及其他常见库。
令人高兴的是,这两个问题都可以一次性解决:页面缓存,内核在其中存储页面大小的文件块。为了说明页面缓存,我将召唤一个名为render的Linux程序,它打开文件scene.dat并一次读取512字节,将文件内容存储到堆分配的块中。第一次阅读是这样的:
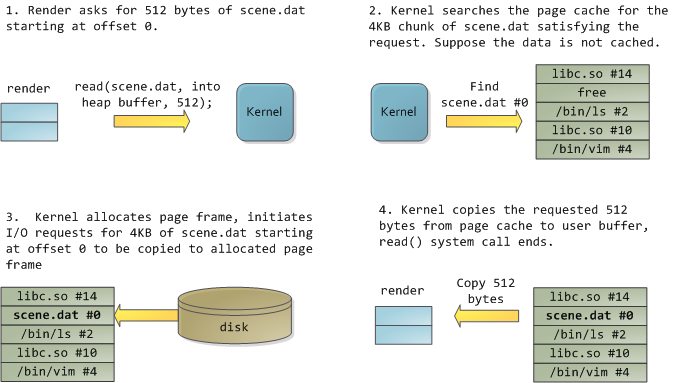
读取12KB后,渲染堆和相关页面帧看起来如下:
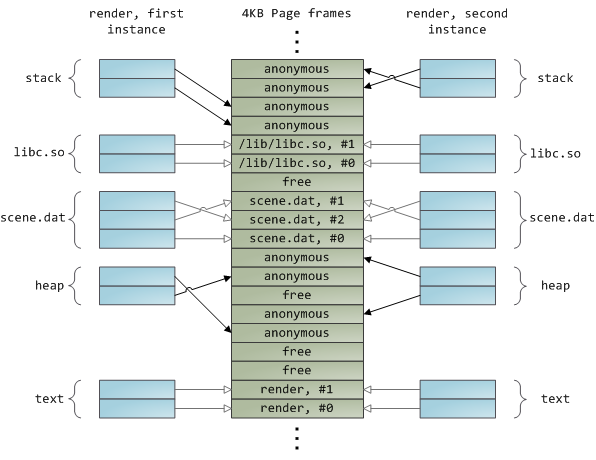
这看起来足够innocent,但发生了很多事情。首先,尽管该程序使用常规读取调用,但三个4KB的页面帧现在在页面缓存中存储了scene.dat的一部分。人们有时会对此感到惊讶,但所有常规文件I/O都通过页面缓存发生。在x86 Linux中,内核将文件视为4KB块的序列。如果您从文件中读取单个字节,则包含您请求的字节的整个4KB块将从磁盘读取并放入页面缓存中。这是有道理的,因为持续的磁盘吞吐量相当不错,程序通常从文件区域读取的不仅仅是几个字节。页面缓存知道文件中每个4KB块的位置,上面显示为#0、#1等。Windows使用类似于Linux页面缓存中的页面的256KB视图。
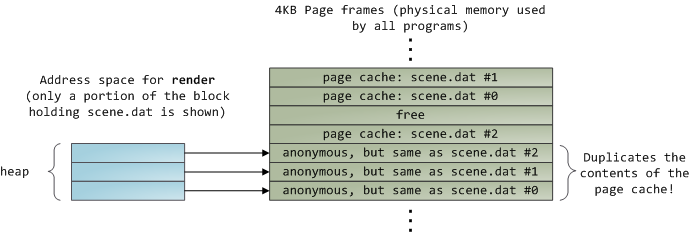
可悲的是,在常规文件读取中,内核必须将页面缓存的内容复制到用户缓冲区中,这不仅需要cpu时间并损害cpu缓存,而且还会浪费重复数据的物理内存。如上图所示,scene.dat内容存储两次,程序的每个实例都会额外存储内容。我们已经缓解了磁盘延迟问题,但在其他方面都惨遭失败。内存映射文件(Memory-mapped files)是摆脱这种疯狂的方法:
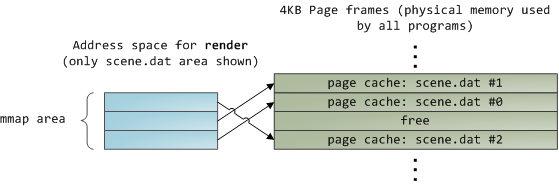
当您使用文件映射时,内核会将程序的虚拟页面直接映射到page cache上。这可以带来显著的性能提升:与常规文件读取相比,Windows系统编程报告了30%及以上的运行时间改进,而Linux和Solaris在Unix环境中的高级编程中也报告了类似的数字。您还可以节省大量物理内存,具体取决于应用程序的性质。
与performance一样,measurement is everything,但内存映射可以保存在程序员的工具箱中。API也非常好,它允许您以内存中的字节身份访问文件,并且不需要代码可读性来换取其好处。注意您的地址空间,并在类Unix系统中尝试mmap、Windows中的CreateFileMapping或高级语言中可用的许多包装器。当您映射文件时,其内容不会一次性进入内存,而是通过页面错误按需进入内存。在获取包含所需文件内容的页面框架后,故障处理程序将您的虚拟页面映射到页面缓存上。如果一开始没有缓存内容,这涉及磁盘I/O。
现在来一个流行测验。想象一下,我们render程序的最后一个实例退出。在页面缓存中存储scene.dat的页面会立即释放吗?人们经常这么认为,但那是个坏主意。仔细想想,我们在一个程序中创建一个文件,退出,然后在第二个程序中使用该文件是很常见的。页面缓存必须处理这种情况。当你更多地考虑它时,为什么内核应该摆脱页面缓存内容?请记住,磁盘比RAM慢5个数量级,因此页面缓存命中是一个巨大的胜利。只要有足够的可用物理内存,缓存就应该保持满。因此,它不依赖于一个特定的过程,而是一个系统范围的资源。如果您从现在起一周后运行渲染,并且scene.dat仍然被缓存,bonus!这就是为什么内核缓存大小稳步攀升,直到达到上限。这不是因为操作系统是垃圾,占用了你的RAM,它实际上是良好的行为,因为在某种程度上,自由的物理内存是一种浪费。最好尽可能多地使用这些东西进行缓存。
由于页面缓存架构,当程序调用write()字节时,只需复制到页面缓存,页面被标记为脏。磁盘I/O通常不会立即发生,因此您的程序不会阻止等待磁盘。缺点是,如果计算机崩溃,您的写入将永远不会成功,因此数据库事务日志等关键文件必须是fsync() ed(尽管人们仍然必须担心驱动器控制器缓存,oy!)。另一方面,读取通常会阻止您的程序,直到数据可用。内核使用急切加载来缓解这个问题,例如提前阅读,内核将几页预加载到页面缓存中,以期待您的读取。您可以通过提供有关您计划是按顺序还是随机读取文件的提示来帮助内核调整其急切加载行为(请参阅madvise()、readahead()、Windows缓存提示)。Linux对内存映射文件进行提前读取,但我不确定Windows。最后,可以在Linux中使用O_DIRECT或在Windows中使用NO_BUFFERING绕过页面缓存,这是数据库软件经常做的事情。
文件映射可以是私有的或共享的。这仅指对内存中内容的更新:在私有映射中,更新不会提交到磁盘或对其他进程可见,而在共享映射中,它们会。内核使用由页表条目启用的写入机制复制来实现私有映射。在下面的示例中,render和另一个名为render3d的程序私有映射scene.dat。然后,render写入其映射文件的虚拟内存区域:
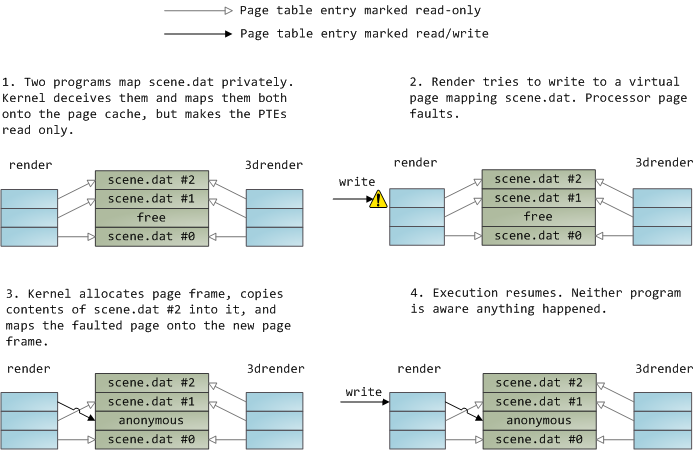
上面显示的只读页面表条目并不意味着映射是只读的,它们只是共享物理内存直到最后一刻的内核技巧。你可以看到“私有”有点用词不当,直到你记得它只适用于更新。这种设计的一个结果是,私有映射文件的虚拟页面会看到其他程序对文件所做的更改,只要页面仅从中读取。一旦写入时复制完成,就不再看到其他人的更改。内核不能保证这种行为,但这是你在x86中得到的,从API的角度来看是有意义的。相比之下,共享映射只是映射到页面缓存上,仅此而已。更新对其他进程可见,并最终出现在磁盘中。最后,如果上述映射是只读的,页面错误将触发分割错误,而不是写入时复制。
动态加载的库通过文件映射带入程序的地址空间。这没有什么神奇之处,它与您通过常规API获得的私有文件映射相同。下面是一个示例,显示了文件映射渲染程序的两个运行实例的部分地址空间,以及物理内存,以将我们看到的许多概念绑定在一起。
CPU如果要访问外部磁盘上的文件,需要首先将这些文件的内容拷贝到内存中,由于硬件的限制,从磁盘到内存的数据传输速度是很慢的,如果现在物理内存有空余,干嘛不用这些空闲内存来缓存一些磁盘的文件内容呢,这部分用作缓存磁盘文件的内存就叫做page cache。
用户进程启动read()系统调用后,内核会首先查看page cache里有没有用户要读取的文件内容,如果有(cache hit),那就直接读取,没有的话(cache miss)再启动I/O操作从磁盘上读取,然后放到page cache中,下次再访问这部分内容的时候,就又可以cache hit,不用忍受磁盘的龟速了(相比内存慢几个数量级)。
和CPU里的硬件cache是不是很像?两者其实都是利用的局部性原理,只不过硬件cache是CPU缓存内存的数据,而page cache是内存缓存磁盘的数据,这也体现了memory hierarchy分级的思想。
相对于磁盘,内存的容量还是很有限的,所以没必要缓存整个文件,只需要当文件的某部分内容真正被访问到时,再将这部分内容调入内存缓存起来就可以了,这种方式叫做demand paging(按需调页),把对需求的满足延迟到最后一刻,很懒很实用。
page cache中那么多的page frames,怎么管理和查找呢?这就要说到之前的文章提到的address_space结构体,一个address_space管理了一个文件在内存中缓存的所有pages。这个address_space可不是进程虚拟地址空间的address space,但是两者之间也是由很多联系的。
这篇文章讲到,mmap映射可以将文件的一部分区域映射到虚拟地址空间的一个VMA,如果有5个进程,每个进程mmap同一个文件两次(文件的两个不同部分),那么就有10个VMAs,但address_space只有一个。
每个进程打开一个文件的时候,都会生成一个表示这个文件的struct file,但是文件的struct inode只有一个,inode才是文件的唯一标识,指向address_space的指针就是内嵌在inode结构体中的。在page cache中,每个page都有对应的文件,这个文件就是这个page的owner,address_space将属于同一owner的pages联系起来,将这些pages的操作方法与文件所属的文件系统联系起来。
struct address_space {
struct inode *host; /* Owner, either the inode or the block_device */
struct radix_tree_root page_tree; /* Cached pages */
spinlock_t tree_lock; /* page_tree lock */
struct prio_tree_root i_mmap; /* Tree of private and shared mappings */
struct spinlock_t i_mmap_lock; /* Protects @i_mmap */
unsigned long nrpages; /* total number of pages */
struct address_space_operations *a_ops; /* operations table */
...
}
- host指向address_space对应文件的inode。
- address_space中的page cache之前一直是用radix tree的数据结构组织的,tree_lock是访问这个radix tree的spinlcok(现在已换成xarray)。
- i_mmap是管理address_space所属文件的多个VMAs映射的,用priority search tree的数据结构组织,i_mmap_lock是访问这个priority search tree的spinlcok。
- nrpages是address_space中含有的page frames的总数。
- a_ops是关于page cache如何与磁盘(backing store)交互的一系列operations。
从Radix Tree到XArray
Radix tree的每个节点可以存放64个slots(由RADIX_TREE_MAP_SHIFT设定,小型系统为了节省内存可以配置为16),每个slot的指针指向下一层节点,最后一层slot的指针指向struct page(关于struct page请参考这篇文章),因此一个高度为2的radix tree可以容纳64个pages,高度为3则可以容纳4096个pages。
如何在radix tree中找到一个指定的page呢?那就要回顾下struct page中的mapping和index域了,mapping指向page所属文件对应的address_space,进而可以找到address_space的radix tree,index既是page在文件内的offset,也可作为查找这个radix tree的索引,因为radix tree就是按page的index来组织struct page的。
具体的查找方法和使用VPN做索引的page table(参考这篇文章)以及使用PPN做索引的sparse section查找(参考这篇文章)都是类似的。这里是用page index中的一部分bits作为radix tree第一层的索引,另一部分bits作为第二层的索引,以此类推。因为一个radix tree节点存放64个slots,因此一层索引需要6个bits,如果radix tree高度为2,则需要12个bits。
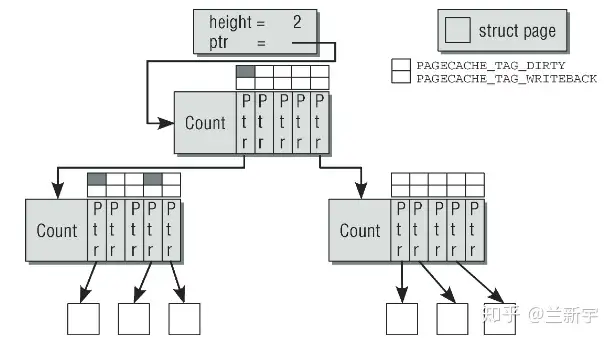
内核中具体的查找函数是find_get_page(mapping, offset),如果在page cache中没有找到,就会触发page fault,调用__page_cache_alloc()在内存中分配若干物理页面,然后将数据从磁盘对应位置copy过来,通过add_to_page_cache()–>radix_tree_insert()放入radix tree中。在将一个page添加到page cache和从page cache移除时,需要将page和对应的radix tree都上锁。
Linux中radix tree的每个slot除了存放指针,还存放着标志page和磁盘文件同步状态的tag。如果page cache中一个page在内存中被修改后没有同步到磁盘,就说这个page是dirty的,此时tag就是PAGECACHE_TAG_DIRTY。如果正在同步,tag就是PAGECACHE_TAG_WRITEBACK。
只要下一层中有一个slot指向的page是dirty的,那么上一层的这个slot的tag就是”dirty”的(就像一滴墨水一样,放入清水后,清水也就不再完全清澈了)。前面介绍struct page中的flags时提到,flags可以是PG_dirty或PG_writeback,既然struct page中已经有了标识同步状态的信息,为什么这里radix tree还要再加上tag来标记呢?
因为page数量众多,内核不可能为每一个page维护一个timer,因此在判断是否应该writeback时,是以inode为单位的,而一个inode对应的address space中,有很多是dirty的page,很多是clean的,clean的page不需要writeback。
在遍历radix tree的过程中,如果去逐一比对每个page的”PG_dirty”标志位,将做很多无用功。而当slot也加上”dirty”标志位后,那么如果slot是clean的,就没有必要再扫描其下一层的slot和page了,这样可以减少开销。
想想进程虚拟地址空间中管理VMA的red black tree(参考这篇文章),这个叫radix tree长的跟我们平时见到的树好像不太一样啊,它的每一个节点更像是一个指针数组吧。所以啊,现在address_space中radix tree已经被xarray取代了(参考这篇文章)。
Reverse Mapping
如果要回收page cache中一个页面,可不仅仅是释放掉那么简单,别忘了Linux中进程和内核都是使用虚拟地址的,多少个PTE页表项还指向这个page呢,回收之前,需要将这些PTE中P标志位设为0(not present),同时将page的物理页面号PFN也全部设成0,要不然下次PTE指向的位置存放的就是无效的数据了。可是struct page中好像并没有一个维护所有指向这个page的PTEs组成的链表。
前面的文章说过,struct page数量极其庞大,如果每个page都有这样一个链表,那将显著增加内存占用,而且PTE中的内容是在不断变化的,维护这一链表的开销也是很大的。那如何找到这些PTE呢?
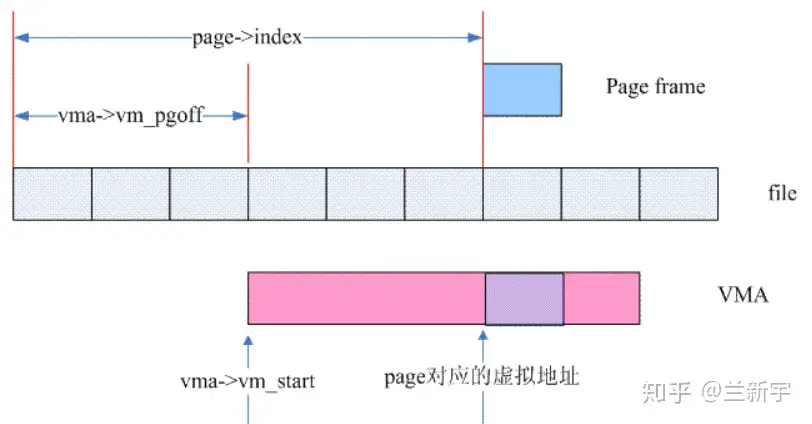
从虚拟地址映射到物理地址是正向映射,而通过物理页面寻找映射它的虚拟地址,则是reverse mapping(逆向映射)。page的确没有直接指向PTE的反向指针,但是page所属的文件是和VMA有mmap线性映射关系的啊,通过page在文件中的offset/index,就可以知道VMA中的哪个虚拟地址映射了这个page。
在代码中的实现是这样的:
__vma_address(struct page *page, struct vm_area_struct *vma)
{
pgoff_t pgoff = page_to_pgoff(page);
return vma->vm_start + ((pgoff - vma->vm_pgoff) << PAGE_SHIFT);
}
映射了某个address_space中至少一个page的所有进程的所有VMAs,就共同构成了这个address_space的priority search tree(PST)。
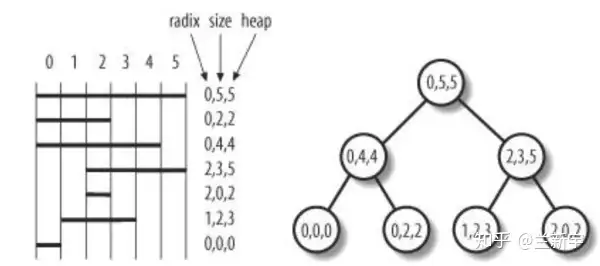
PST是一种糅合了radix tree和heap的数据结构,具体实现较为复杂,现在已经被基于augmented rbtree的interval tree所取代,详情请参考这篇文章。
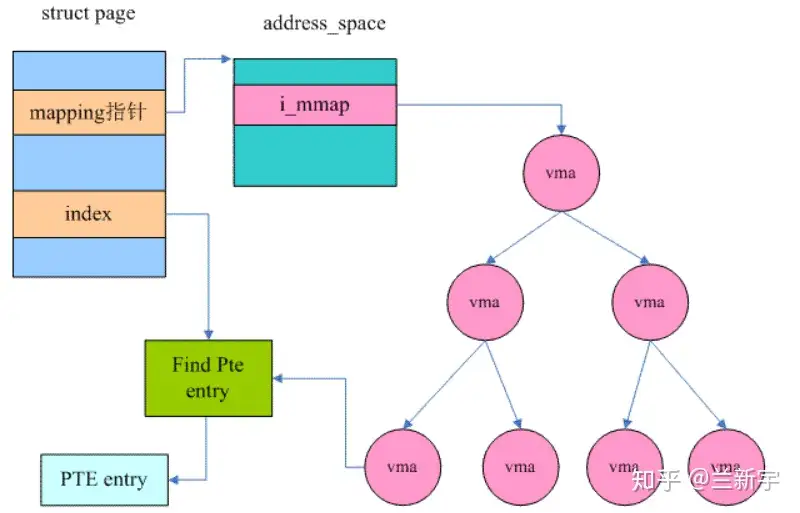
对比一下,一个进程所含有的所有VMAs是通过链表和红黑树组织起来的,一个文件所对应的所有VMA是通过基于红黑树的interval tree组织起来的。因此,一个VMA被创建之后,需要通过vma_link()插入到这3种数据结构中。
__vma_link_list(mm, vma, prev, rb_parent);
__vma_link_rb(mm, vma, rb_link, rb_parent);
__vma_link_file(vma);