
内存管理是操作系统的核心;它对编程和系统管理都至关重要。在接下来的文章中,我将着眼于实际方面来涵盖记忆,但不会回避内部。虽然这些概念是通用的,但示例大多来自32位x86上的Linux和Windows。文章描述了程序如何在内存中布局。
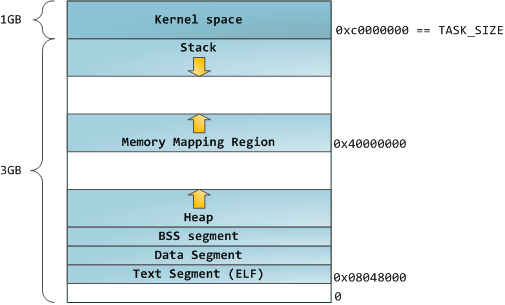
多任务操作系统中的每个进程都在自己的内存沙盒中运行。这个沙盒是虚拟地址空间,在32位模式下,它始终是一个4GB的内存地址块。这些虚拟地址通过页表映射到物理内存,这些页表由操作系统内核维护,并由处理器查阅。每个进程都有自己的一套页表,但有一个陷阱。一旦启用虚拟地址,它们将应用于机器中运行的所有软件,包括内核本身。因此,部分虚拟地址空间必须保留给内核:
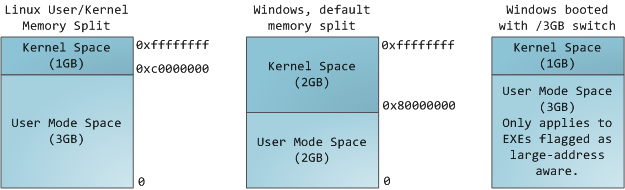
这并不意味着内核使用那么多的物理内存,只是它拥有那部分地址空间来映射它想要的任何物理内存。内核空间在页表中标记为专属于特权代码(环2或更低),因此,如果用户模式程序尝试触摸它,则会触发页面错误。在Linux中,内核空间不断存在,并在所有进程中映射相同的物理内存。内核代码和数据始终可寻址,随时准备处理中断或系统调用。相比之下,每当发生进程切换时,地址空间用户模式部分的映射都会发生变化:
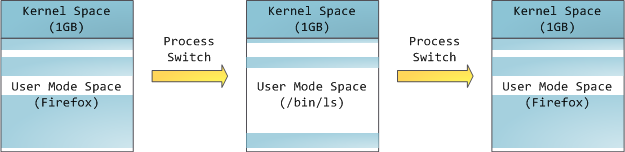
蓝色区域表示映射到物理内存的虚拟地址,而白色区域则未映射。在上面的例子中,由于其内存饥饿,Firefox使用了更多的虚拟地址空间。地址空间中的不同频段对应于内存段,如堆栈、堆栈等。请记住,这些段只是一系列内存地址,与英特尔风格的段无关。无论如何,这是Linux进程中的标准段布局:
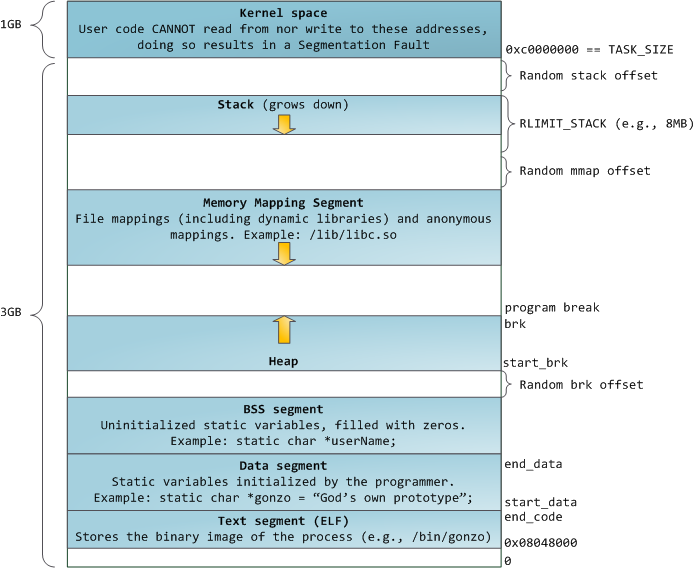
当计算过程安全稳定时,上面所示段的起始虚拟地址对机器中的几乎每个进程都完全相同。这使得远程利用安全漏洞变得容易。漏洞通常需要引用绝对内存位置:堆栈上的地址、库函数的地址等。远程攻击者必须盲目选择此位置,并指望地址空间都是一样的。当他们被时,人们会被pwned。因此,地址空间随机化变得流行起来。Linux通过向其起始地址添加偏移量来随机化堆栈、内存映射段和堆。不幸的是,32位地址空间非常小,几乎没有随机化的空间,并阻碍了其有效性。
进程地址空间中最上面的部分是堆栈 (stack),它存储大多数编程语言中的局部变量和函数参数。调用方法或函数会将新的堆栈框架推送到堆栈上。当函数返回时,堆栈框架将被销毁。这种简单的设计,可能是因为数据遵循严格的LIFO顺序,这意味着不需要复杂的数据结构来跟踪堆栈内容——一个简单的指向堆栈顶部的指针即可。因此,推送和弹出是非常快速和确定性的。此外,堆栈区域的持续重用往往会将活动堆栈内存保留在cpu缓存中,从而加快访问速度。进程中的每个线程都有自己的堆栈。
通过推送超出其容纳范围的数据,可以耗尽堆栈的区域映射。这触发了一个页面错误,该错误在Linux中由expand_stack()处理,然后调用acct_stack_growth()来检查是否适合增长堆栈。如果堆栈大小低于RLIMIT_STACK(通常为8MB),那么通常堆栈会增长,程序会快乐地继续,不知道刚刚发生了什么。这是堆栈大小根据需求调整的正常机制。但是,如果已达到最大堆栈大小,我们将有一个堆栈溢出,并且程序会收到一个分段故障。虽然映射的堆栈区域会扩展以满足需求,但当堆栈变小时,它不会缩减。
动态堆栈增长是访问未映射的内存区域(如上图所示)可能有效的唯一情况。对未映射内存的任何其他访问都会触发页面故障,从而导致分段故障。一些映射区域是只读的,因此对这些区域的写入尝试也会导致segfaults。
在堆栈下方,我们有内存映射段。在这里,内核将文件的内容直接映射到内存。任何应用程序都可以通过Linux mmap()系统调用或Windows CreateFileMapping() / MapViewOfFile()请求此类映射。内存映射是一种方便且高性能的文件I/O方式,因此它用于加载动态库。也可以创建一个不对应于任何文件的匿名内存映射,而不是用于程序数据。在Linux中,如果您通过malloc()请求大块内存,C库将创建这样的匿名映射,而不是使用堆内存。“大”表示大于MMAP_THRESHOLD字节,默认为128 kB,可通过mallopt()进行调节。
堆提供运行时内存分配,就像堆栈一样,用于数据比执行分配的函数活得更久的情况,这与堆栈不同。大多数语言为程序提供堆管理。因此,满足内存请求是语言运行时和内核之间的共同事务。在C中,堆分配的接口是malloc()和相关函数,而在像C#这样的GC语言中,接口是new关键字。
如果堆中有足够的空间来满足内存请求,它可以由语言运行时处理,而无需内核参与。否则,堆通过brk()系统调用放大,为请求的块腾出空间。堆管理很复杂,需要复杂的算法,在面对我们程序的混沌分配模式时,努力实现速度和高效的内存使用。服务堆请求所需的时间可能差异很大。实时系统有特殊用途的分配器来处理这个问题。堆也变得支离破碎,如下所示:

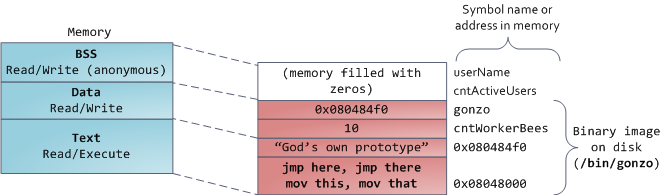
最后,我们到达内存的最低段:BSS、数据和程序文本。C中静态(全局)变量的BSS和数据存储内容。区别在于,BSS存储未初始化静态变量的内容,其值不是由程序员在源代码中设置的。BSS内存区域是匿名的:它不映射任何文件。
另一方面,数据段包含源代码中初始化的静态变量的内容。这个内存区域不是匿名的。它映射程序二进制映像中包含源代码中给出的初始静态值的部分。因此,如果写出static int cntWorkerBees = 10,则cntWorkerBees的内容存在于数据段中,并以10开头。尽管数据段映射了一个文件,但它是一个私有内存映射,这意味着内存的更新不会反映在底层文件中。必须如此,否则对全局变量的赋值将更改磁盘上的二进制映像。不可思议!
图表中的数据示例更棘手,因为它使用指针。在这种情况下,指针gonzo的内容 - 一个4字节的内存地址 - 存在于数据段中。然而,它所指向的实际字符串没有。字符串位于文本段中,该段是只读的,除了字符串文字等花絮外,还存储了您的所有代码。文本段还会在内存中映射您的二进制文件,但写入此区域会使您的程序获得分段故障。这有助于防止指针错误,尽管一开始就不像避免C那样有效。以下是显示这些段和我们的示例变量的图表:
您可以通过读取文件/proc/pid_of_process/maps来检查Linux进程中的内存区域。请记住,一个段可能包含许多区域。例如,每个内存映射文件通常在mmap段中都有自己的区域,而动态库具有类似BSS和数据的额外区域。下一个帖子将澄清“区域”的真正含义。此外,有时人们说“数据段”意味着所有数据+bss+堆。
您可以使用nm和objdump命令检查二进制图像,以显示符号、其地址、段等。最后,上面描述的虚拟地址布局是Linux中的“灵活”布局,几年来一直是默认布局。它假设我们有RLIMIT_STACK的值。如果不是这样,Linux会恢复到如下所示的“经典”布局:
这就是虚拟地址空间布局。下一篇文章[How the kernel manages memory]讨论了内核如何跟踪这些内存区域。接下来,我们将研究内存映射,文件读写如何与这一切联系起来,以及内存使用数字意味着什么。