
堆的定义
一个序列R[0..n-1], 关键字分别为k0、k1、… 、kn-1
该序列满足如下性质(简称堆性质)
-
$k_i <= k_{2i+1}$ 且 $k_i<=k_{2i+2}$
-
$k_i >= k_{2i+1}$ 且$k_i >= k_{2i+2}$
满足1为小根堆,满足2为大根堆。下文讨论的是大根堆
补充所用性质
完全二叉树的一些性质:0…n-1的树节点,对于编号为i的节点,父节点为(i-1)/2(下取整),两个子节点为 2i+1, 2i+2。树节点数为n, 最后一个非叶子节点的序号为n/2 - 1
向下筛选算法
void siftDown(vector<int>& R,int low,int high)
//R[low..high]的自顶向下筛选
{ int i=low;
int j=2*i+1; //R[j]是R[i]的左孩子
int tmp=R[i]; //tmp临时保存根结点
while (j<=high) //只对R[low..high]的元素进行筛选
{ if (j<high && R[j]<R[j+1])
j++; //若右孩子较大,把j指向右孩子
if (tmp<R[j]) //tmp的孩子较大
{ R[i]=R[j]; //将R[j]调整到双亲位置上
i=j; j=2*i+1; //修改i和j值,以便继续向下筛选
}
else break; //若孩子较小,则筛选结束
}
R[i]=tmp; //原根结点放入最终位置
}
向上筛选算法
void siftUp(vector<int>& R,int j) //自底向上筛选:从叶子结点j向上筛选
{ int i=(j-1)/2; //i指向R[j]的双亲
while (true)
{ if (R[j]>R[i]) //若孩子较大
swap(R[i],R[j]); //交换
if (i==0) break; //到达根结点时结束
j=i; i=(j-1)/2; //继续向上调整
}
}
堆排序算法的思路:
-
先对序列进行筛选,从非叶子节点(n/2 - 1)开始,向序号为0开始筛选,初始化堆
-
将根节点(最大)放在树的最后,循环进行。最后层次遍历二叉树(这里用vector作为二叉树的存储结构,层次遍历就是顺序遍历vector即可),即可从小到大输出序列
堆排序算法
void HeapSort(vector<int>& R,int n) //堆排序
{ for (int i=n/2-1;i>=0;i--) //从最后一个分支结点开始循环建立初始堆
siftDown(R,i,n-1); //对R[i..n-1]进行筛选
for (int i=n-1;i>0;i--) //进行n-1趟排序,每一趟后无序区元素个数减1
{ swap(R[0],R[i]); //将无序区中尾元素与R[0]交换,扩大有序区
siftDown(R,0,i-1); //对无序区R[0..i-1]继续筛选
}
}
算法分析
- 对于高度为h的堆,一次向下筛选所需要进行的关键字比较次数至多为2(h-1) //每一层比较两次
- 对n个关键字的,建成h=$\lfloor log_2n + 1\rfloor$的堆
- 调整堆顶n-1次,总共比较次数不超过 2($\lfloor log_2(n-1)\rfloor$ + $\lfloor log_2(n-2)\rfloor$ + … +$log_22$) < $2nlog_2n$
时间复杂度为O($nlog_2n$)
空间复杂度为O(1)
堆数据结构
线性表存储
-
append(e) 插入元素e
-
pop()返回堆顶元素并且删除
-
gettop()取堆顶元素
-
empty()判断堆是否空
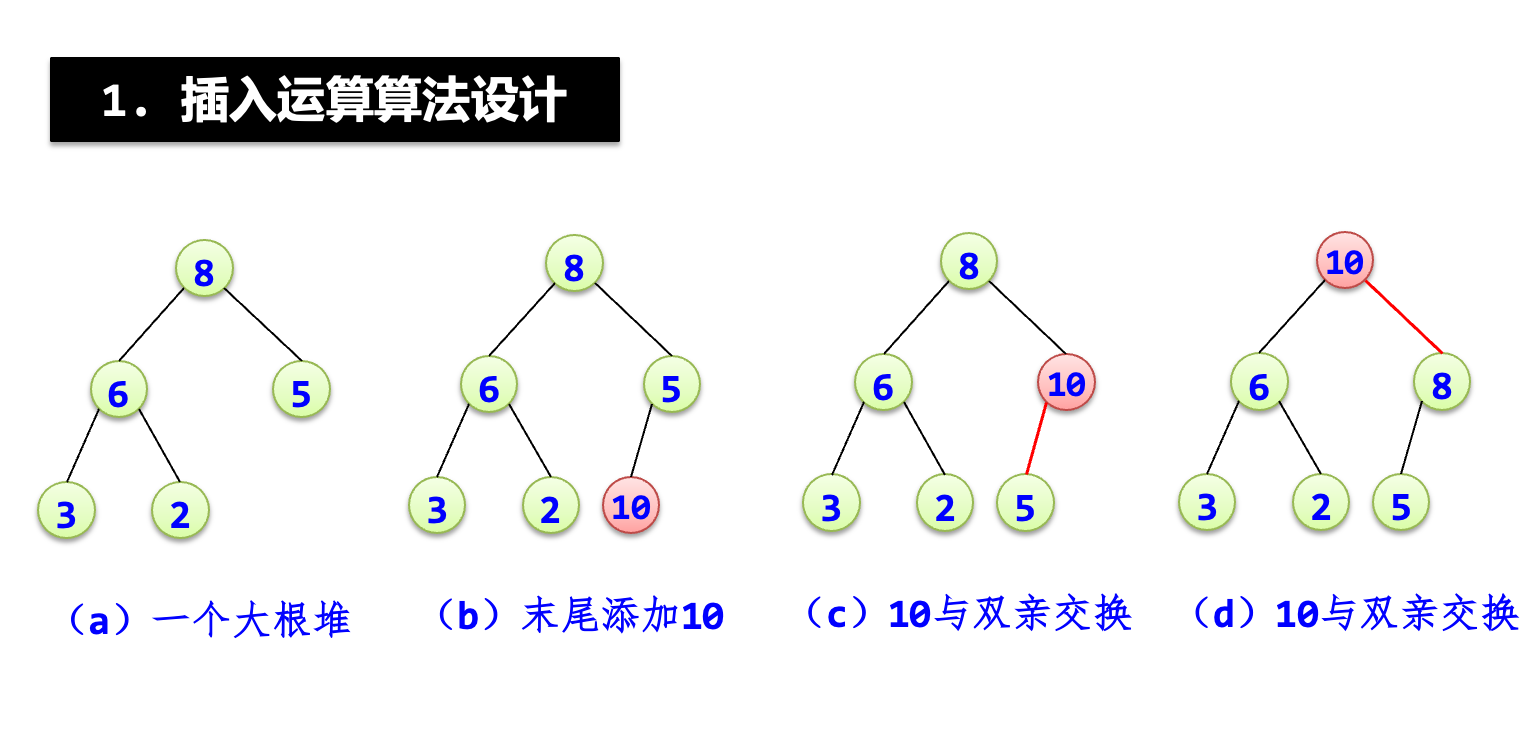

template <typename T>
class Heap //堆数据结构的实现(默认大根堆)
{ int n; //堆中元素个数
vector<T> R; //用R[0..n-1]存放堆中元素
public:
Heap():n(0) {} //构造函数
void siftDown(int low,int high) //R[low..high]的自顶向下筛选
{ int i=low;
int j=2*i+1; //R[j]是R[i]的左孩子
T tmp=R[i]; //tmp临时保存根结点
while (j<=high) //只对R[low..high]的元素进行筛选
{ if (j<high && R[j]<R[j+1])
j++; //若右孩子较大,把j指向右孩子
if (tmp<R[j]) //tmp的孩子较大
{ R[i]=R[j]; //将R[j]调整到双亲位置上
i=j; j=2*i+1; //修改i和j值,以便继续向下筛选
}
else break; //若孩子较小,则筛选结束
}
R[i]=tmp; //原根结点放入最终位置
}
void siftUp(int j) //自底向上筛选:从叶子结点j向上筛选
{ int i=(j-1)/2; //i指向R[j]的双亲
while (true)
{ if (R[i]<R[j]) //若孩子较大,则交换
swap(R[i],R[j]);
if (i==0) break; //到达根结点时结束
j=i; i=(j-1)/2; //继续向上调整
}
}
//堆的基本运算算法
void push(T e) //插入元素e
{ n++; //堆中元素个数增1
if (R.size()>=n) //R中有多余空间
R[n-1]=e;
else //R中没有多余空间
R.push_back(e); //将e添加到末尾
if (n==1) return; //e作为根结点的情况
int j=n-1;
siftUp(j); //从叶子结点R[j]向上筛选
}
T pop() //删除堆顶元素
{ if (n==1)
{ n=0;
return R[0];
}
T e=R[0]; //取出堆顶元素
R[0]=R[n-1]; //用尾元素覆盖R[0]
n--; //元素个数减少1
siftDown(0,n-1); //筛选为一个堆
return e;
}
T gettop() //取堆顶元素
{
return R[0];
}
bool empty() //判断堆是否为空
{
return n==0;
}
};
堆排序是一种高效的排序算法,具有一些明显的优势和一些局限性
- 时间复杂度:
- 堆排序的平均时间复杂度为O(n log n),与快速排序和归并排序相当。
- 在最坏情况下,堆排序仍然保持O(n log n)的时间复杂度,而快速排序的最坏情况为O(n^2)。
- 堆排序的时间复杂度在各种情况下都非常稳定,不受输入数据的分布情况影响。
- 空间复杂度:
- 堆排序的空间复杂度为O(1),因为它仅需要一个固定大小的辅助堆数据结构来完成排序,不需要额外的内存空间。
- 归并排序需要O(n)的额外空间用于存储临时数据,而快速排序通常需要O(log n)的递归堆栈空间。
- 稳定性:
- 堆排序是不稳定的,即相同元素的相对位置可能会在排序后发生变化。
- 归并排序是稳定的,它可以保持相同元素的相对位置不变。
- 实现复杂性:
- 堆排序的实现相对来说比较复杂,需要构建和维护堆结构,因此在实际应用中可能不如快速排序或归并排序容易实现。
- 快速排序的实现相对简单,并且性能通常很好。
- 适用场景:
- 堆排序在需要高度稳定性的排序任务中不适用,因为它是不稳定的。
- 堆排序在内存有限的情况下非常有用,因为它的空间复杂度很低。
- 快速排序通常在大多数情况下表现良好,但在最坏情况下可能性能下降。
- 归并排序适用于需要稳定性且内存空间足够的情况。
总之,堆排序是一种稳定的、高效的排序算法,特别适用于内存有限的情况下。但是,根据具体的排序任务和要求,选择最合适的排序算法可能会有所不同。其他排序算法如快速排序和归并排序也有它们自己的优点和适用场景,所以在选择算法时需要考虑问题的特点和性能需求。